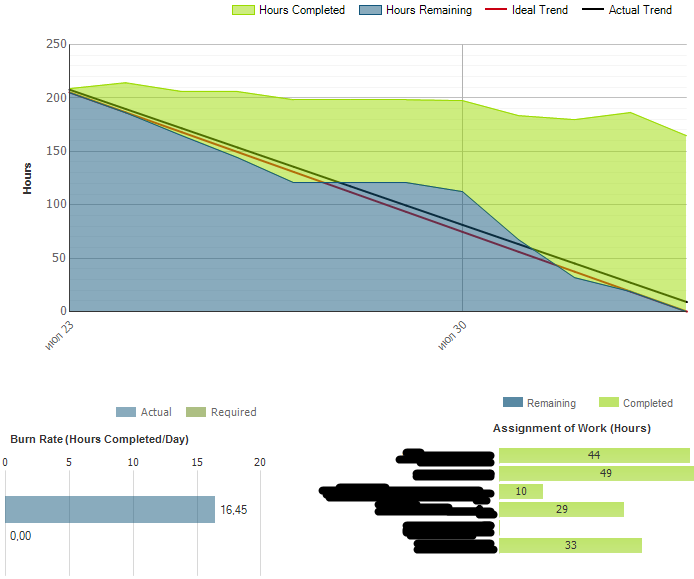
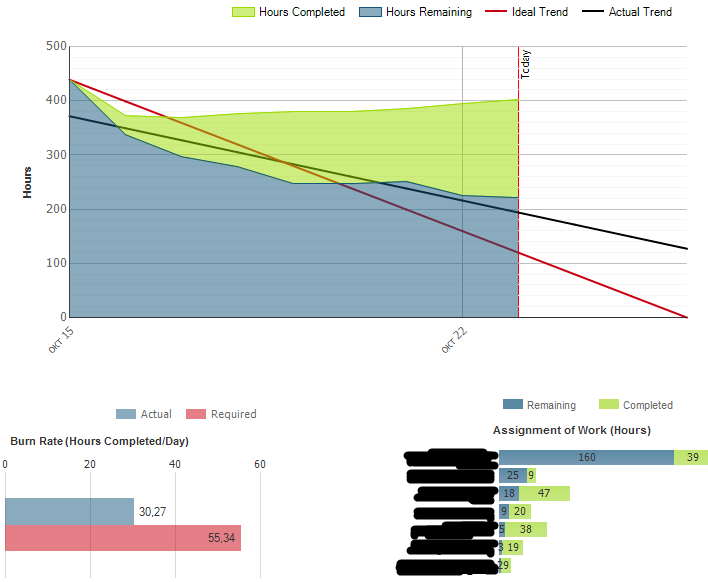
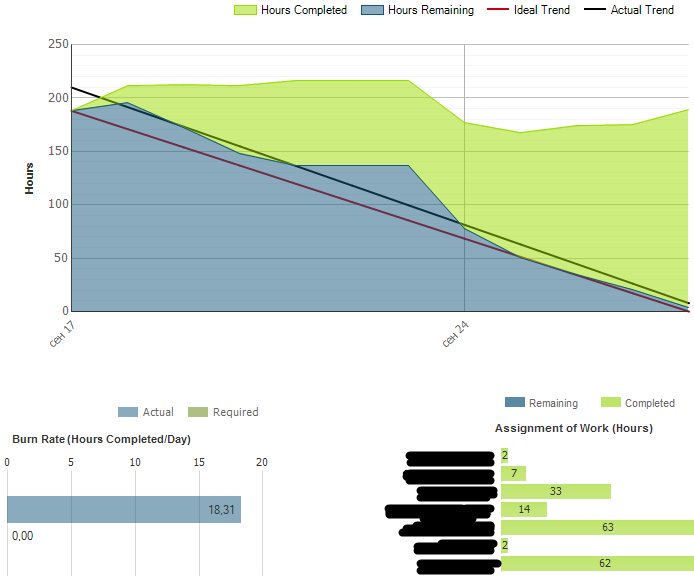
Я недавно писал о том, как пользоваться отчетом Burndown and Burn Rate в TFS.
Сейчас хочу рассказать немного про внутреннюю кухню. Как же данные из issue tracker, например значения полей remaining work и completed work у элементов task, превращаются красивую картинку отчета?
На самом деле, никакой магии здесь нет. Всё предельно просто.
Данные issue tracker хранятся в обычной БД SQL Server с именем TFS_имяколлекциипроектов. Обычная такая транзакционная БД. С немного страшной структурой, ну с кем не бывает, и в MS страшные вещи проектируют.
Например work items скорее всего лежат в какой-то из этих таблиц (а может и во всех сразу): WorkItemsAre, WorkItemsWere, WorkItemsLatest, WorkItemsDestroyed, с любопытными полями вроде “Not A Field” и “Fld10013”.
Нет, данные из этих таблиц не идут напрямую на картинку отчета.
Раз в 2 минуты (по умолчанию) TFS перекидывает данные в data warehouse (склад данных). БД TFS_Warehouse. Обычный такой data warehouse, с таблицами фактов, таблицами измерений. Зачем это делается? Профиль нагрузки на транзакционную БД и на data warehouse очень разный. Транзакционная БД должна хранить только текущее состояние данных, и обеспечивать обработку большого количества запросов чтения/записи. Data warehouse должен хранить огромные объемы (в идеале – всю историю изменений рабочих элементов TFS), при этом данные там не изменяются и не удаляются, только добавляются. Структура базы данных оптимизирована для использования в отчетах и аналитике.
Далее раз в 2 часа (по умолчанию) данные попадают в OLAP-кубы SQL Server Analysis Services (база данных Tfs_Analysis в SSAS). При этом там производятся всякие расчеты хитрые, например предварительный расчет различных агрегированных показателей, для того чтобы потом быстро отвечать на аналитические запросы.
И только после этого, SQL Server Reporting Services на основе данных из SQL Server Analysis Services строит отчеты. Они строятся тоже не в real-time по запросу пользователя, а периодически обновляются в фоновом режиме. Как часто – уже не помню, но чаще чем 1 раз в час.
Время последнего обновления данных в SSAS обычно указывается в отчете снизу справа с подписью “Data updated”. Время последнего обновления отчета в SQL Server Reporting Services – там же, с подписью “Generated”.
В разработке собственных отчетов (или правке стандартных) тоже нет никакой магии. Это обычные отчеты SQL Server Reporting Services.
Если зайти в веб-интерфейс SQL Server Reporting Services, найти там список отчетов, у каждого отчета в контекстном меню есть пункт “Edit in report builder”.
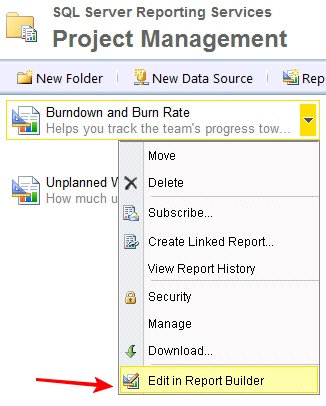
Он открывает report builder – GUI-приложение, которое инсталлируется через Click once, и позволяет полноценно редактировать отчет.
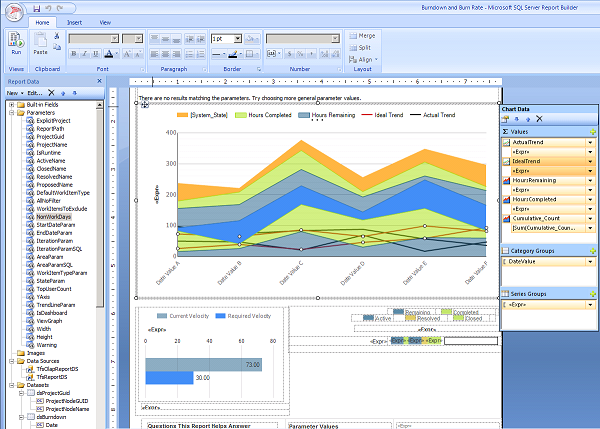
Тут мы можем настраивать источники данных, привязывать их к элементам отчета, стили всякие настраивать.
Посмотрим на то, откуда берутся данные для отчета Burn Rate. Он строится на основе набора данных dsVelocity, который берет данные из SSAS с помощью вот такого MDX-запроса:
WITH
MEMBER [Measures].[Remaining Work] AS [Measures].[FactCurrentWorkItem Microsoft_VSTS_Scheduling_RemainingWork]
MEMBER [Measures].[Completed Work] AS [Measures].[FactCurrentWorkItem Microsoft_VSTS_Scheduling_CompletedWork]
SELECT
{
[Measures].[Work Item Count],
[Measures].[Remaining Work],
[Measures].[Completed Work]
} ON COLUMNS,
{
NonEmpty(
[Work Item].[System_State].[System_State],
[Measures].[Work Item Count]
)
} ON ROWS
FROM
(
SELECT
CrossJoin(
StrToMember("[Team Project].[Project Node GUID].&[{" + @ProjectGuid + "}]"),
StrToSet(@StateParam),
StrToSet(@AreaParam),
StrToSet(@IterationParam),
Except(
Descendants(StrToSet(@WorkItemTypeParam)),
[Work Item].[System_WorkItemType].[All] + StrToSet(@WorkItemsToExclude)
)
) ON COLUMNS
FROM [Team System]
)
Просто взяли данные по рабочим элементам, отфильтровали по параметрам, из мер (measure) нас интересуют количество рабочих элементов, оставшаяся и выполненная работа. Я не до конца этот запрос понимаю, но при желании разобраться можно.
Дальше для вычисления собственно current velocity и required velocity используются вот такие нехитрые выражения:
CurrentVelocity =IIF(
Parameters!YAxis.Value = "hours",
Fields!Completed_Work.Value,
IIF(
Fields!System_State.Value=Parameters!ClosedName.Value,
Fields!Cumulative_Count.Value,
0
)
) / Code.DaysCompleted(Parameters!StartDateParam.Value, Parameters!EndDateParam.Value, Parameters!NonWorkDays.Value)
RequiredVelocity =IIF(
Parameters!YAxis.Value = "hours",
Fields!Remaining_Work.Value,
IIF(
Fields!System_State.Value<>Parameters!ClosedName.Value,
Fields!Cumulative_Count.Value,
0
)
) / Code.DaysRemaining(Parameters!StartDateParam.Value, Parameters!EndDateParam.Value, Parameters!NonWorkDays.Value)
Если отбросить кучерявые конструкции IIF, видно, что здесь работа делится на рабочие дни. Нерабочие дни при этом вычисляются с использованием параметра “NonWorkDays”, значение по умолчанию у которого равно “0,6” – подозреваю, что это индексы воскресенья и субботы соответственно.
Домашнее задание: отредактируйте график Burndown так, чтобы в нём не было выходных дней. И еще придумайте, как нам быть с тем, что сейчас в России заканчиваются 3-дневные выходные, а значит, график Burn Rate будет врать.
–
Павел Сурменок
http://surmenok.ru/
http://pavel.surmenok.com/